Schaalbaarheid is belangrijk vanuit zakelijk oogpunt omdat het bepaalt in hoeverre bedrijven de toenemende vraag aankunnen, grote projecten beheren en duurzaam groeien.
Flyvbjerg (2021) definieert schaalbaarheid als het vermogen om iets in omvang of schaal te veranderen, bijvoorbeeld het potentieel voor een entiteit om een groeiende –of afnemende– werkdruk aan te kunnen. In tegenstelling tot wat vaak wordt gedacht, is groot zijn niet hetzelfde als schaalbaar zijn. Schaalbaarheid is het vermogen om in grootte te veranderen, inclusief het vermogen om snel groot te worden, maar schaalbaarheid is niet identiek aan grootte op zich.
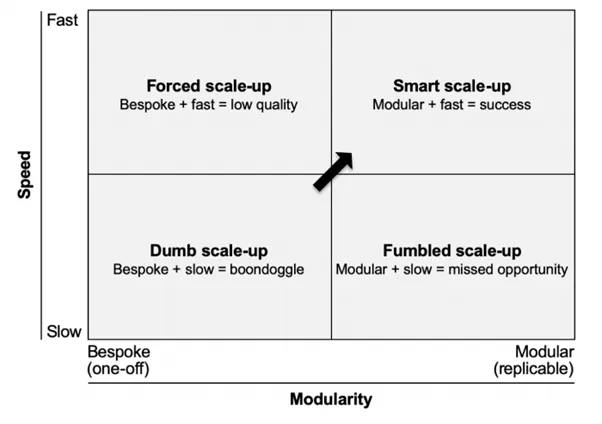
Budget overschreden, met vertraging, ondermaatse voordelen, keer op keer, is een uitdrukking die Bent Flyvbjerg in 2017 gebruikte om de staat van de meeste grote projecten samen te vatten, vaak omdat ze niet goed schalen. Denk bij deze projecten aan kernreactoren, wolkenkrabbers en grote IT-systemen. Hoewel ze er heel verschillend uitzien, kunnen ze allemaal beter worden gepland, ontworpen, beheerd en uitgevoerd om de kans op succes te vergroten en projectrisico’s op een vergelijkbare manier te minimaliseren. Daarom deed Flyvbjerg in 2021 onderzoek naar veel grote projecten en ontdekte hij vier manieren om ze op te schalen, zoals geïllustreerd in de onderstaande figuur. Hij ontdekte ook dat reproduceerbare modulariteit en snelheid van planning tot levering het succes van dergelijke projecten bepalen.
Het belang van repliceerbare modulariteit
Alvorens in te gaan op het belang van repliceerbare modulariteit, worden repliceerbaarheid en modulariteit als volgt gedefinieerd:
– Repliceerbaarheid verwijst naar de eigenschap van een systeem, netwerk of proces dat het mogelijk maakt om het modulair op een andere locatie of tijd te dupliceren.
– Modulariteit verwijst naar het al dan niet verdelen van een oplossing in onderling afhankelijke componenten. Hoge modulariteit leidt tot een hoog schaalbaarheidspotentieel. Bij de analyse van schaalbaarheid wordt rekening gehouden met modulariteit.
Flyvbjerg beschreef twee grote voordelen van repliceerbare modulariteit in grote projecten.
Ten eerste is een modulair ontwerp dat kan worden hergebruikt en gerepliceerd de blauwdruk voor projecten die kunnen samengesteld worden uit vrij stabiele standaardmodules die hun waarde eerder hebben bewezen en dus al eerder zijn getest. Dit verlaagt de projectmanagementrisico’s aanzienlijk in vergelijking met projecten met op maat gemaakte componenten die in het verleden nauwelijks zijn getest.
Ten tweede creëert het vertrouwen op stabiele repliceerbare modules een feedbacklus waarin mensen kunnen experimenteren en hun ervaringen, klachten en andere zaken kunnen delen die kunnen leiden tot verdere verbeteringen in de module. Die verbeteringen zullen ook reproduceerbaar zijn. Bovendien maakt repliceerbaarheid het voor gebruikers van een module ook gemakkelijker om problemen en oplossingen voor toekomstige versies en andere gebruikers te vinden. Een belangrijke succesfactor van elke populaire technologiestack, zoals Java of Django, is hun gestandaardiseerde ondersteuning voor modules waar ze een ecosysteem en community rond of meer repositories voor herbruikbare componenten hebben gecreëerd. Dergelijke standaardmodules maken het voor ontwikkelaars veel gemakkelijker om te experimenteren en functionaliteiten te bedenken die door eindgebruikers kunnen worden getest dan in het geval van het zelf ontwikkelen van elke module. Deze feedbacklus en experimenten door middel van repliceerbare modules creëren wat Flyvbjerg positief leren noemt, wat hij definieert als Dingen sneller, beter en goedkoper leren doen door steeds hetzelfde te doen, via gerepliceerde modules.
Het tegenovergestelde van positief leren is negatief leren. Dit is de situatie waarin hoe meer mensen aan een project werken, hoe meer ze beseffen dat het project complexer zal worden, langer zal duren en meer zal kosten dan gedacht; op hun beurt raken deze mensen meer gefrustreerd en wordt hun moreel lager. Dit gebeurt wanneer men iets probeert te schalen dat niet goed schaalt.
Het belang van snelheid
Flyvbjerg benadrukt het belang van snelheid bij het opleveren van projecten en hij verwijst naar de eerste prognosewet, of de First Law of Forecasting:
First Law of Forecasting: u hebt relatieve zekerheid voor het eerste jaar van een prognose en u moet vergeten dat u veel weet over iets dat langer duurt dan drie tot vijf jaar.
Met andere woorden, deze wet stelt dat hoe langer het duurt om een resultaat te bereiken, hoe meer het zal afwijken van het gewenste resultaat. Deze variantie vertaalt zich direct in een lagere voorspelbaarheid en hogere projectrisico’s. Het verkorten van projecttijdframes helpt projectrisico’s te minimaliseren en dit is een sleutel tot projectsucces. Er moet worden vermeld dat het tijdsbestek van de First Law of Forecasting niet van toepassing is op bepaalde verschijnselen in de echte wereld, zoals weersvoorspellingen en levensverwachting. Een weersvoorspelling heeft slechts een korte tijdsnauwkeurigheid van maximaal tien dagen. Aan de andere kant kan de levensverwachting veel nauwkeuriger en voor een veel breder tijdsbestek van meerdere decennia worden voorspeld.
De First Law of Forecasting is alleen van toepassing op verschijnselen die kunnen worden voorspeld en die verschijnselen zijn met regressie naar het gemiddelde. Het is niet van toepassing op fenomenen met regressie naar de staart die niet kunnen worden voorspeld. Dit leidt tot wat Flyvbjerg de tweede prognosewet noemt:
Second Law of Forecasting: je moet alleen proberen te voorspellen wat werkelijk voorspelbaar is en nooit doen alsof iets voorspelbaar wanneer dat niet het geval is.
Ondanks de beperkingen van de First Law of Forecasting, kan deze tweede wet enorm helpen bij projectbeheer voor domeinen waar deze van toepassing is. In dergelijke domeinen vertelt de wet twee dingen:
1. Een Minimum Viable Product (MVP) hebben en dit leveren binnen het eerste jaar na de beslissing om ermee door te gaan.
2. De oplevering, of in ieder geval een substantieel deel daarvan, binnen drie tot vijf jaar hebben afgerond. Alles buiten deze tijdshorizon zal veel willekeuriger zijn en veel minder kans van slagen hebben.
Snelle opschaling is cruciaal in tech-economieën, met Silicon Valley als epicentrum. Dat komt omdat concurrentie in technologie wordt gekenmerkt door winner-takes-all, dus snelheid is cruciaal voor concurrentievoordeel, zoals uitgelegd door Eric Schmidt, voormalig voorzitter en CEO van Alphabet: Maak een product, verzend het, kijk hoe het werkt, ontwerp en implementeer verbeteringen en duw het weer naar buiten. Verzenden en herhalen. De bedrijven die het snelst zijn in dit proces zullen winnen.
Repliceerbare modulariteit en snelheid samen
Snelheid is slechts de helft van het verhaal, want snelheid zonder reproduceerbare modulariteit kan veel meer schade aanrichten dan wat ook. De combinatie van snelheid en reproduceerbare modulariteit stelt projectleiders in staat om snelheid op een stabiele en betrouwbare manier te bereiken en te beheren zonder de veiligheid en kwaliteit in gevaar te brengen. Dit proces van opschalen op een snelle maar betrouwbare manier wordt vaak blitzscaling genoemd.
Vier manieren om op te schalen
We komen terug op de figuur hierboven en bespreken de vier manieren waarop men in principe kan schalen. Alleen de Smart scale-up leidt tot succes.
1. Smart scale-up
Smart scale-up verwijst naar het ontwikkelen van iets groots op basis van de principes van modulariteit, repliceerbaarheid en snelheid. Projecten bestaan uit op zichzelf staande onderdelen van een groter project die al waarde kunnen leveren aan de eindgebruiker. De gigafabrieken van Tesla bestaan bijvoorbeeld uit verschillende repliceerbare modules die in zeer hoge mate kunnen werken zonder dat de andere zijn gebouwd. Dit stelt mensen in staat om projecten op een nogal incrementele manier te ontwikkelen waarbij elke module op zichzelf inkomsten kan genereren. Bovendien kunnen deze modules binnen een jaar of minder worden geleverd, waardoor positief leren wordt gemaximaliseerd en tot betrouwbaardere projectprognoses wordt geleid. Dit is verreweg de beste vorm van scale-up en waar organisaties naar moeten streven.
Meestal is er een afweging tussen snelheid en kwaliteit bij het produceren van iets op maat. In het geval van slimme opschaling die vertrouwt op repliceerbaar modulair ontwerp en snelheid, is een dergelijke afweging niet langer nodig. In softwareontwikkeling zijn cloudservices een voorbeeld van slimme opschaling waarmee organisaties en gebruikers rekenkracht en opslag veel sneller en repliceerbaarder kunnen opschalen via zaken als Infrastructure as Code in vergelijking met on-premises infrastructuur.
2. Dumb scale-up
Dumb scale-up is het ontwerpen en ontwikkelen van een project als een grote, traag op maat gemaakt monolithisch systeem dat pas waarde kan opleveren na voltooiing. In tegenstelling tot slimme opschaling zijn deze projecten nogal binair –ze zijn al dan niet voltooid– wat betekent dat een project nutteloos is, zelfs als het tot 95% is voltooid. Bovendien duurt het ontwikkelen van zo’n monoliet vaak langer dan 5 jaar, waardoor projectprognoses gevaarlijk onbetrouwbaar zijn. Daarom wordt dit soort opschaling gekenmerkt door kostenoverschrijdingen en vertragingen in de oplevering van projecten. Door iets op te schalen dat niet gemakkelijk kan worden geschaald, zullen mensen die aan een dumb scale-up project werken, zich realiseren dat het project moeilijker zal zijn en meer zal kosten dan verwacht naarmate ze er meer ervaring in krijgen (negatief leren). In softwareontwikkeling zijn twee voorbeelden van zulke opschaling de ontwikkeling van een big-bang ERP-systeem of een monolithisch data warehouse.
3. Forced scale-up
Een gedwongen opschaling is een maatwerkoplossing die onder druk van stakeholders in hoog tempo is opgeleverd. Het is echter erg moeilijk om in korte tijd iets op maat te bouwen en daarom is het resultaat waarschijnlijk van lage kwaliteit met een hoge mate van technical debt. Deze lage kwaliteit vertaalt zich in veiligheidsproblemen en meer. Deze vorm van opschaling kan zelfs als erger worden beschouwd dan de Dumb scale-up, omdat het sneller middelen verspilt en z’n snelheid behaalt ten koste van veiligheid en kwaliteit.
4. Fumbled scale-up
Dit is een beter oplossing, maar toch slechter dan slimme scale-up. Het betreft de ontwikkeling van een modulair project op basis van een repliceerbaar ontwerp op een nogal trage manier. Modulariteit, reproduceerbaarheid en hergebruik zouden normaal gesproken tot snelheid moeten leiden, maar bij dit soort opschaling is de snelheid laag als gevolg van een gebrek aan kapitaal, personeel, managementondersteuning of andere factoren. Het leidt vaak tot gemiste kansen.